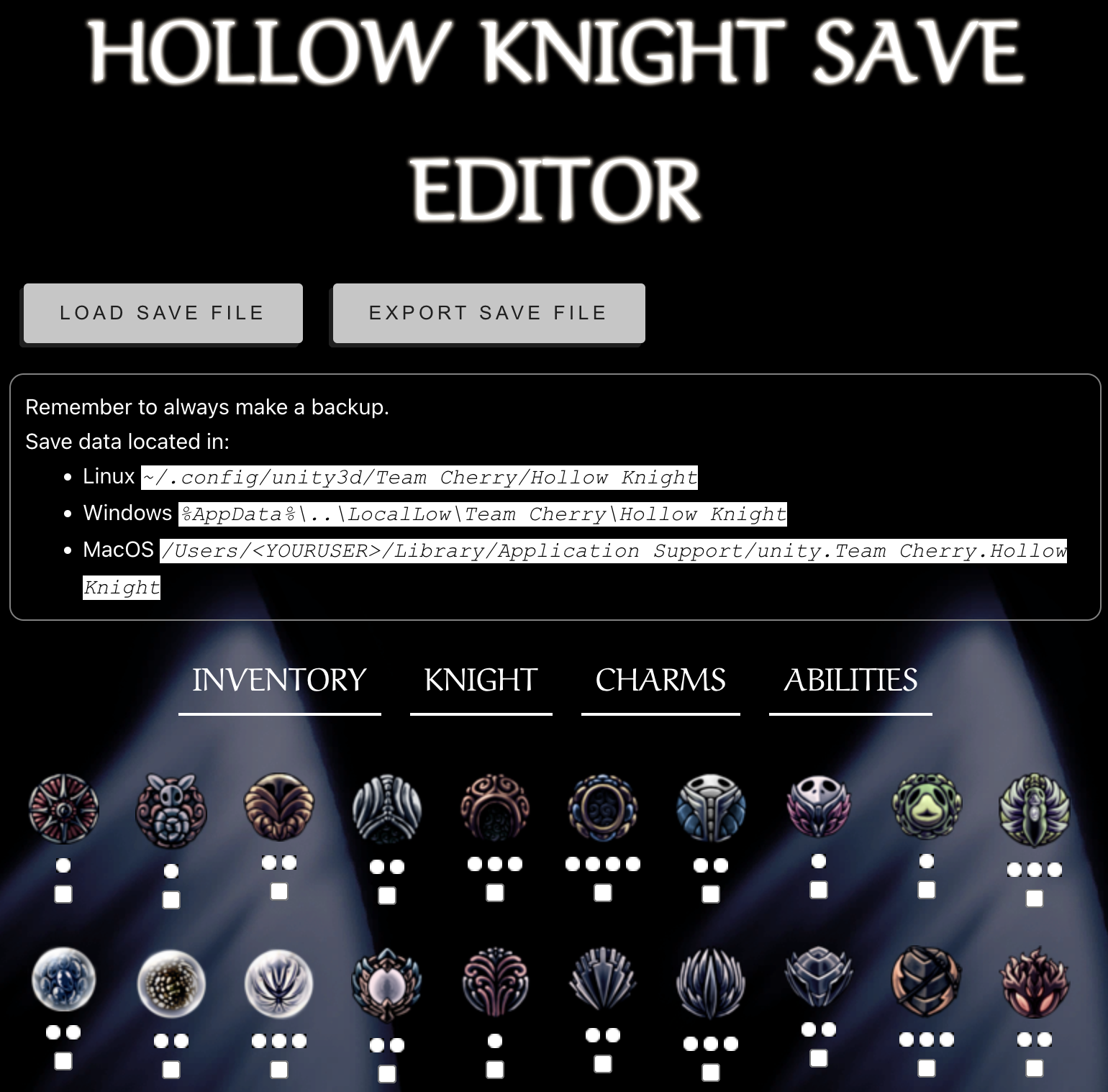
I made a simple Hollow Knight save game editor website at https://hollowedit.com. This is a small postmortem on that project.
Initial Inspiration
Sometime near the start of this year I had a discussion with a friend and we decided that we wanted to do a small side-project together.
We decided to create a Hollow Knight save game editor website. The project came to mind because:
- Hollow Knight’s a cool game
- the technologically hard problem was already solved (there were existing save game editors)
- existing editors either require a desktop application or manually editing some json
This meant to us that there was a niche that could be filled by a simple web-based editor that doesn’t require users to be very technical. All that would be required is using the systems file-manager and basic web-browser interaction.
Tech Stack consideration
My friend was mostly focusing on python and had used flask previously. I’m familiar enough with python from writing mostly small utilities and using it as a “portable shell script”. So that’s what we used for the backend.
For the frontend we looked around what was trending around that time. React, Vue and Svelte were the contenders. I thought React was too un-intuitive for such a small project, because when previously working with it I sometimes felt a bit lost about the control-flow. Vue and Svelte both seemed like a fine choice. I was a bit more familiar with Vue and it seemed to have better TypeScript support (and as a die-hard static typing fan I always try to use TS when JS is required). So we chose Vue.
Do we even need a backend? Not really, but we wanted to get coding as quickly as possible and it seemed easier solve the decryption/encryption done in a backend.
That was about as sophisticated as our research was before getting started.
Implementation Learnings
Most of the implementation went fairly smooth. We had the site running locally in dev mode within the weekend we started. Some polishing and the deployment setup took a lot longer and was stretched over a handful of sessions afterwards.
Encryption
I ported the symmetric encryption/decryption already reversed by KayDeeTee/Hollow-Knight-SaveManager in Java to python. Which initially worked, but I had to fix a bug in my port later on in the padding. I fixed it by examining the Hollow Knight de-compilation (dnSpy is really neat when dealing with Unity games).
So I guess some testing with more varied input would’ve been in order if this was for a more serious project.
The Vue Options/Composition APIs
While we did get something running in the first weekend we were very unfortunate with the timing.
Unbeknownst to us the new Vue3 documentation wasn’t out yet. It would be released a week later and includes a very handy little switch to view all examples in either the Options API or the Composition API styles. Not having used the vue composition API before but seeing examples of it mixed in with the documentation led to quite some confusion. Some very deeply confused code resulted that mixed the two in unfortunate ways.
Some weeks after the documentation was releases I ported the handful of Components we had to be very clearly in the Composition API style and it cleaned up a lot of the very ad-hoc bolted together code.
This really underscored the importance of robust documentation for me once again. It also highlighted the value of using technology you’re already familiar with at a conceptual level when trying to get something done quickly. Learning Vue 3 enough to directly apply it to a project without taking time to understand the underlying concepts turned out to be a fool’s errant.
Deployment can look very different than dev
When preparing to publish the site somewhere I knew how to deploy the Vue frontend, but did not previously publish anything flask-based. In development we just used flask run for quick testing. But for deployment it’s very understandably not recommended. So I looked at the official documentation which assumes the code is in a python package. This was not the case yet, since we just used a collection of local python Modules up to this point.
I thought “this should be easy to add, it’s already running with the dev server”. Never having created a python package before I headed to the setuptools documentation. I followed their guide and created a simple pyproject.toml. But then I kept running into import errors which I could not explain to myself. After hours of tinkering and trying to find out what I had done differently now I found out that I didn’t know much about how python handles imports in detail. It turns out when running code inside a package the import statement behaves a little differently.
The proper thing to do would be to just always treat the code as if it’s running in a package and use editable packages. But I was somewhat annoyed by having wasted so much time on diagnosing the issue. So as a punishment to the pythonic gods I instead opted to do this ugly hack to import the same module two different ways depending on whether it’s imported from within the package or not.
# try both file-local and package local imports
# THIS IS A HACK, don't do this in actual code
try:
from SaveEncoder import SaveEncoder
except:
from .SaveEncoder import SaveEncoder
The final deployment setup then was made way too complicated. Having learned my lesson by now to just use what I was at least somewhat familiar with I opted to just build two separate Docker images and glue them together in a docker-compose config. But enough text for now, time for you to look at an unnecessary an ugly graph:
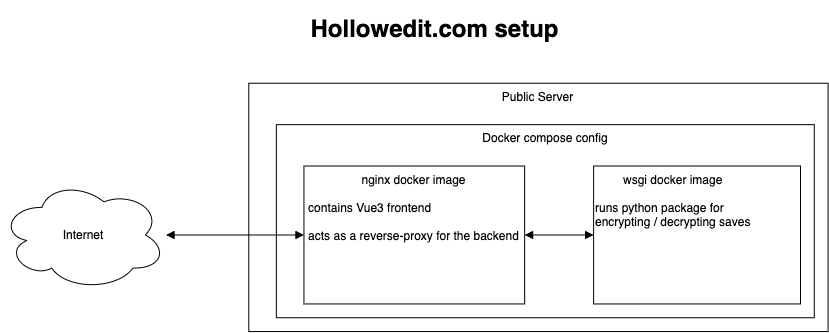
When I saw there was a sale on .com domains I snapped up hollowedit.com , setup the Let’s Encrypt certificate for the domain et voil`a the site was online.
Closing thoughts
This was a fun little project and I’m glad I did it. I learned a lot about Vue specifically and it’s a neat tool to have in my back pocket.
I don’t usually do websites for fun. I’m more drawn to native development in my free time. But this was a great change up and being able to simply pass around a link is always a plus of working with web-tech.
In addition to it being a good learning experience I hope it can be useful to a couple of people.